Infini-attention是一种新型的注意力机制,它通过引入压缩记忆的方式优化了传统的注意力机制。这种压缩记忆的特点在于,它能够通过调整参数来存储和回忆信息,而不是随着输入序列的增长而增加内存需求。此外,Infini-attention还巧妙地将局部注意力与长期线性注意力结合在单个Transformer块内,进一步提升了模型的性能。
为了验证Infini-attention的有效性,研究者们在一系列长上下文语言建模任务上进行了测试,包括1M序列长度的passkey上下文块检索任务和500K长度的书籍摘要任务。这些实验使用了不同规模的大型语言模型(LLMs),具体为1B和8B两种。实验结…
北大团队与兔展合作开发的Open Sora项目在视频生成技术上取得了重大突破,该项目支持生成高分辨率且时长超过10秒的视频,并且这些视频的内容还能通过文本进行控制。Open Sora项目在开源社区中也获得了极高的关注,已经得到了6.6k的星标认可。最新版本的Open-Sora-Plan v1.0.0不仅能够生成高清视频,还实现了对华为昇腾910b AI芯片的推理支持,并计划未来能够支持国产算力进行训练。在技术层面,项目采用了CausalVideoVAE模型架构,这一架构通过联合训练图像和视频数据,并引入了创新的初始化方法,大幅提升了模型的性能。此外,在训练过程中,项目采用了多阶段级联训练方法,…
Open Sora团队最近推出了一个新的视频生成项目,名为MagicTime。该项目专注于创造变形时光延续视频,这类视频能够展示如花朵绽放、冰块融化等自然过程。MagicTime的特点是它能够学习和应用现实世界的物理规律,以生成更加真实和生动的视频效果。
为了实现这一目标,团队首先开发了MagicAdapter技术。这项技术通过分别对空间和时间进行处理和训练,有效地从变形视频中提取了大量的物理知识。此外,MagicAdapter还使得预训练的T2V模型得以应用,从而能够生成这类具有物理规律的视频。
除了MagicAdapter,项目还引入了一种动态帧提取策略。这种策略特别适合用于变形时光延…
近期,Cohere 推出了最新的基础模型——Rerank 3,这款模型专为提升企业搜索和检索增强生成(RAG)系统而设计。Rerank 3 能够与任何数据库或搜索索引兼容,并且可以轻松集成到任何具有原生搜索功能的遗留应用程序中。仅需一行代码,Rerank 3 就能提升搜索性能或降低运行 RAG 应用程序的成本,同时对延迟的影响微乎其微。
Rerank 3 在企业搜索领域提供了先进的功能,包括能够处理长达 4k 的上下文长度,显著提高了长篇文档的搜索质量;能够搜索多方面和半结构化数据,比如电子邮件、发票、JSON 文档、代码和表格;支持 100 多种语言的多语言覆盖;提高的响应速度和更低的总拥…
近期的趋势显示,生成式人工智能正在极大地提升企业和行业的生产力。企业通用生产力类别的公司数量有了显著增长,而且随着人工智能在各个行业的深入应用,如图像编辑、视频生成和游戏构建等领域,消费者和专业用户之间的界限变得模糊。此外,新的工业领域也开始涌现,例如机器人、工业维护和自动驾驶等,展示了人工智能与硬件结合的潜力。
展望未来,人工智能的发展预示着一场新的生产力革命,它将重塑商业模式和工业未来,就像个人电脑一样。随着人工智能技术的进步,它们将能够协同工作,甚至可能参与到公司构建和管理中,使得公司运营变得更加高效和灵活。未来的公司可能会拥有新的所有权和管理结构,并且对于企业产品的需求也会发生变化,…
Patchscopes是一个新兴的框架,旨在通过利用大型语言模型(LLMs)自身的语言能力,来统一和解释其内部工作机制的各种先前方法。该框架通过自然语言解释模型内部隐藏的表示方式,提供了直观的理解。
随着大型语言模型的显著进步,人们对其准确性和透明度的担忧也日益增加,因此理解这些模型的工作机制变得尤为重要,尤其是在模型出现错误的情况下。通过探索机器学习模型如何表示其所学习到的内容(即模型的隐藏表示),我们可以更好地控制模型的行为,并深入科学地了解这些模型的实际工作方式。这一点随着深度神经网络的复杂性和规模的增长而变得越来越重要。最近在可解释性研究方面的进展,展示了使用LLMs来解释另一个模型…
生成式人工智能(Generative AI)引发了一系列前所未有的创新浪潮。这项技术使我们能够与对话式人工智能进行交流、生成逼真的图像,并通过简单的提示来准确总结大量文档。截至目前,Llama模型已超过1亿次下载,这些创新很大程度上得益于开放模型的推广。
为了推动这一创新浪潮的安全发展,建立信任至关重要,这需要在负责任的人工智能方面进行更多的研究和贡献。开发者不能孤立地面对人工智能的挑战,因此我们希望营造一个开放、共享的环境,创建一个开放信任和安全的中心。
今天,我们宣布推出Purple Llama项目,这是一个旨在随着时间推移,整合工具和评估,帮助社区以开放的生成式AI模型负责任地构建的…
百度创始人、董事长兼CEO李彦宏在近期一次内部讲话中就当前AI领域的几个热议话题分享了自己的观点。针对“大模型开源还是闭源”的问题,李彦宏解释了百度选择不开源的原因。他认为,市场上已经存在足够多的开源大模型,如国际上的Llama、Mistral和国内的智源、百川、阿里通义等,因此百度开源与否对市场影响不大。此外,他强调闭源模型能够在能力上持续领先,并且不需要维护额外的开源版本,这对百度而言更加经济高效。
李彦宏还指出,模型开源并不如Linux、安卓等软件开源那样能带来集体进步的效应,因为开源模型往往是在小规模和零散的方式下进行验证应用,而没有经过大规模算力的检验。他进一步阐述,闭源模型具备真…
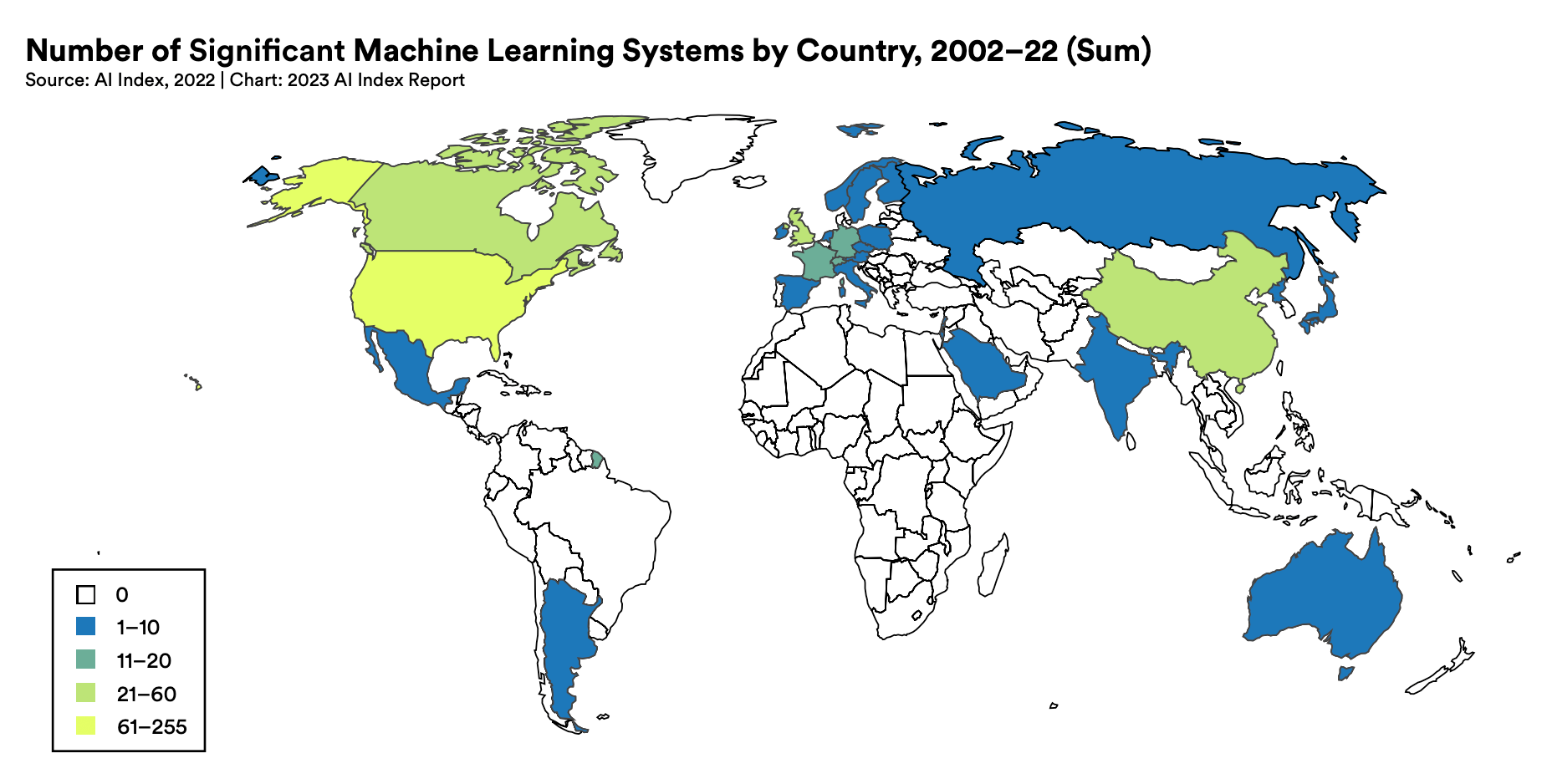
斯坦福大学人类与AI合作研究所(HAI)最近发布了2023年的人工智能指数报告,这份长达400页的报告通过详尽的数据分析和精心设计的可视化图表,全面审视了人工智能行业的发展状况。报告指出,自2014年以来,产业界在AI发展上已经超越了学术界,到2022年,产业界推出的机器学习模型数量是学术界的10倍以上。这主要是由于创造先进AI系统越来越依赖于大量数据、强大计算能力和充足的资金,而这些正是产业界相对于学术界和非营利组织的优势所在。报告还提到,AI系统在传统基准测试中的表现虽然仍在刷新纪录,但年度改进的幅度却在缩小,性能提升的极限正在加快到来。为了更全面地评估AI性能,出现了如BIG-bench…
澜舟科技的Mengzi3-13B模型已经正式在始智AI的wisemodel.cn开源社区平台上进行发布,并且对学术研究界完全开放使用,同时也支持免费的商业用途。该模型采用了Llama架构,并且选用了来自网页、百科、社交媒体、媒体和新闻等多种渠道的高质量语料,以及一些精选的开源数据集作为训练材料。Mengzi3-13B模型在进行多语言的语料训练时,特别针对万亿级别的tokens进行了深入学习,从而在中文处理能力方面表现卓越,同时也具备了良好的多语言处理能力。在参数量不超过20B的轻量化大型模型中,Mengzi3-13B因其在中英文语言处理方面的出色表现而独树一帜,它不仅具有很高的实用性,而且性价…